We launched SeatGeek’s iPhone app today. I’ve been creating websites for years, but until this project had never made anything native for a phone. As a first-timer, I was struck by some of the differences between web and mobile app design, which I’ll describe below.
First, a caveat: I worked on designing the SeatGeek app but not coding it [1]. What follows is relevant to web/app design more than development.
Designs magically look better on a Retina Display
Retina Displays are rose-colored glasses for Photoshop comps. Take an average design and put it on an Retina Display and it will look above average. Good designs become gorgeous. This discovery makes the whole process more fun. Designing for the Retina Display makes you feel like you have an extra 20% dose of talent. The effect never fully wore off for me; each time I beamed a design from Photoshop to my phone, I was pleasantly surprised [2].
You never know what it’ll look like until it’s on a phone
This is related to the above. Since things look different on a Retina Display, you can’t trust what you see on your computer. Things look better, but they also look different. Texture that seemed over-the-top in Photoshop is almost invisible on a Retina Display. A button that may seem appropriately-sized on your monitor looks far too small on a 320 x 480 display. So I got into the habit of constantly checking my work on a phone. Silkscreen proved invaluable for this; I recommend it.
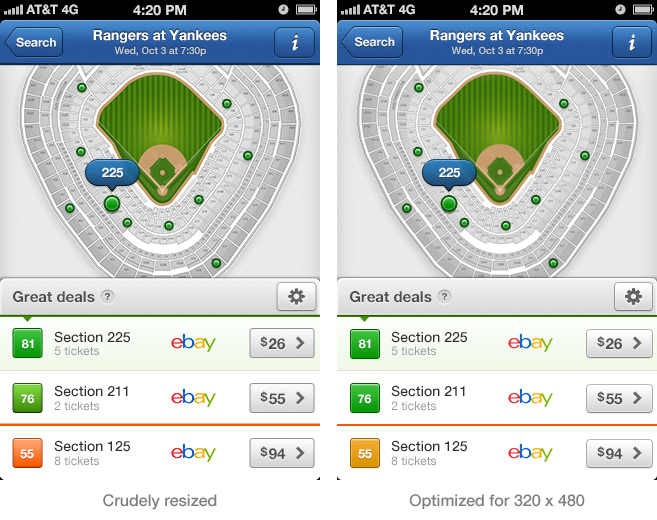
Designing for 1x requires more than just downsizing
My first attempt at turning one of my 2x comps into a 1x version was to just decrease the image size in Photoshop. That was naive. Some elements don’t scale well when simply downsized; they require special attention.
The version is on the left is a 2x PSD with its image size cut in half. The version on the right is the same interface optimized for 1x. There are a number of problems in the left version: the stroke around the options button is fuzzy, the white inner shadow in the upper-right info button lacks clarity, the lower border on the top bar is too strong. These visual bugs are fixed in the optimized version [3].
Then again, maybe you should just downsize and move on
Perhaps it isn’t worth optimizing for 1x. As fewer folks own pre-Retina iPhones, you’re spending a lot of time catering to small group of users. The crudely downsized version isn’t pixel-perfect, but it’s still usable. For all future SeatGeek iOS work, we’re going to approach 1x iPhones like we approach IE7–we’ll make sure that the experience is solid, but won’t require it be perfect.
Simple things can be damn hard
Our app’s home view has a little tagline below the main search bar: “Your ticket to every ticket.”
In the PSD, the word “every” was bolded, which makes the phrase more intuitive. It seemed like a simple thing to implement–there must be an iOS equivalent of the <strong> tag, right? Apparently not. Eric, our CTO, spent a long while messing around with NSAttributedString and a couple of open-source libraries before finally giving up and using an image in the interest of time. We talked to more experienced iOS devs who confirmed that bolding a single word is indeed non-trivial.
Interface iteration is more cumbersome
We should have finalized our design before we began coding. We didn’t, and it created a lot of additional work. On the web, I’m used to a workflow where a backend developer can create a page’s core logic and a designer can then beautify everything. Or the designer can do their work first and the backend engineer can hook up the UI afterwards. That fluidity doesn’t exist with the iPhone. When we wanted to make UI changes late in the game, it slowed everything down.
On the web, a designer is often comfortable with frontend markup. HTML/CSS are accessible and easy to learn, even for those without a programming background. Objective-C is not. So on the iPhone, the technology draws a bigger barrier between the person creating the design and the person implementing it. Iterating on the interface involves more friction [4].
Provisioning and distribution is a nightmare
Want to set up your phone to test local builds of your app? If it’s your first time, hopefully you have the entire afternoon free to figure it out [5]. Otherwise, it’s not going to happen. Want to set up TestFlight so that multiple people can distribute builds? It so was difficult that we never even bothered.
The Xcode/iOS distribution process needs serious work. But distribution inconveniences aside, I had a lot of fun making this app. Most core web design techniques also apply in the iOS world. So someone comfortable building web UI’s can create an interface that looks good on an iPhone without much trouble. If you’re given the chance to design your first iPhone app, jump at it.
[1] I’m a little ashamed about that. I hated the feeling of being helpless when any change needed to be implemented. But that’s how we decided to divvy up the work. For context, I created the wireframes/flows for the app, designed much of it in Photoshop (but I wasn’t the only one…Chris, another engineer at SeatGeek, also played a big part), and did a lot of QA-related things. But my only Objective-C commits were trivial copy changes.
[2] I was working on a MacBook Air and Thunderbolt Monitor, neither of which are Retina. I’m guessing the effect is less pronounced if you have a Retina MacBook Pro.
[3] Most of these issues could be avoided if we always used evenly-spaced elements in the 2x version.
[4] None of this applies if the same person is designing and coding the app, which is clearly preferable.
[5] Or, at least, you’re friends with an experienced iOS developer who can walk you through each arcane step.
Much ado is made about the utilityofkeyboardshortcuts. The more hotkeys you use, the more efficient you’ll be, right? Computer literate people are supposed to avoid the mouse as much as possible. Using a mouse to navigate through a menu tends to be slower than using a shortcut.
But why are button shortcuts limited to keyboards? Mice, after all, have buttons too. The problem is that most mice only have two or three of them. Since those buttons are used for core OS functions, it’s hard for them to also perform shortcuts.
But why do most mice only have 2-3 buttons? It’s a silly restriction! If you put more buttons on a mouse, you get more power.
Unless you’ve managed to transcend into some sort of hyper-zen keyboard/human symbiosis, you still spend part of your day with your hand on a mouse. And when it’s there, if you need to move back to your keyboard to perform a single action, it slows you down.
An example: suppose you’re navigating a webpage with your mouse. You want to move to a different tab in your browser. Most people do one of two things: (1) move the mouse up to the new tab, click it, and then move it back down to the main page or (2) momentarily shift their mouse hand over to the keyboard and press a shortcut that moves browser tabs. But there’s a quicker option: press the button on your mouse that moves browser tabs.
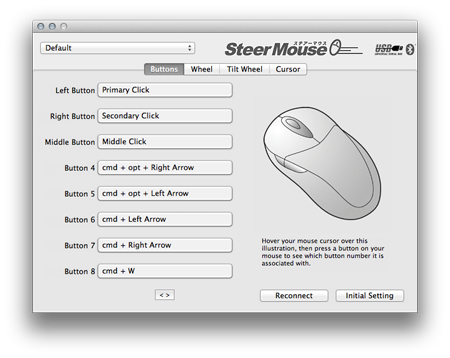
The key is getting a mouse that has such a button. For the past year I’ve been using that kind of mouse. I love it. After trying several options, I settled on the Logitech G700, which has thirteen programmable buttons [1]. If you use a mouse like the G700, you’ll want to use software to manage what those buttons do. I recommend SteerMouse [2]. SteerMouse allows you to set each of those buttons to the tasks you perform most often [3].
I’ve set my mouse shortcuts to facilitate things like closing windows (⌘ + w), moving forward and backwards in a browser (⌘ + ←) and taking a screenshot (⌘ + shift + 4). I’m sure yours will be different, personalized for you. SteerMouse also allows you to set application-specific shortcuts, giving adventurous folks even more flexibly.
In isolation, using a mouse shortcut instead of a keyboard shortcut only saves a fraction of a second. But once you get in the groove, you can use hundreds of mouse shortcuts every day. I estimate that I use about 600 mouse shortcuts per day, each of which saves me about half a second. So the G700/SteerMouse combo saves me about five minutes per day. That’s not a huge amount of time, but it adds up. If you create $200 of value per hour, then hotclicks are worth $6,000 annually.
This is the sort of thing that’s primarily geared towards “professional” computer users–programmers, designers, etc. I won’t be buying G700’s for my parents. You sacrifice some elegance and simplicity when you do this, just as you sacrifice elegance when you use a laptop instead of an iPad to write an email. But most people I know still prefer to write email on a real computer. If you buy a programmable mouse, you may soon feel that using the old 2-button variety feels like using an iPad to compose a very long email.
[1] I chose the G700 because it’s the model that offers the most buttons while still working with SteerMouse and not having mushy buttons (a personal pet peeve). But I wish there were a model that had more buttons; I think that would allow me to be more efficient.
[2] SteerMouse is for OS X. I’m unfamiliar with options for other operating systems.
[3] I’ve spent a lot of time using a Magic Mouse and I really want to like it–the concept of a multi-touch mouse is alluring. But I could never get the damn thing to perform consistently with modded with shortcuts; simple operations like right-clicking had less than 90% success rates.
When you create a new account, Gmail is blazingly fast. For most users, it stays that way forever. But for a minority of heavy users, Gmail gradually degrades towards slower and more painful speeds. Eventually doing simple tasks like sending an email or archiving a chain is downright glacial. Until a few weeks ago, glacial Gmail was part of my life.
The proximate cause of slowness is mailbox size. The alluring promise Google made when they first launched Gmail–that you never again have to delete any message–is not a reality. If a frequent emailer stops deleting messages, she’ll end up with a slow-as-hell mail app. I spent hours deleting as much of my inbox as I could, particularly emails with large attachements, but was still only able to get down to 11GB (I send a lot of email) [1].
I love Gmail as a mail app. Love the interface, love the shortcuts, love the filters, and love the fact that you can mod it with Boomerang [2]. As the iPhone is to phones, Gmail is to mail apps–ever since it launched, everyone else has tried to not-so-subtly replicate it. The problem is, when you saddle a Gmail account with 11GB of history, everything that makes it great becomes painful to use.
So, in a moment of desperation, I tried separating “Gmail the app” from “Gmail the database of messages.” I did the following:
Created a new Gmail account.
Changed the settings in my primary personal and business addresses to forward all messages to the new gmail address, but to keep copies in the original inboxes.
Configured the new account to send mail from the address of my old acount.
Instantly, Gmail became a delight to use. Everything I asked it to do happened instantly. No more twenty second delays between clicking the “sent” link and actually seeing my sent messages. I felt dramatically more productive.
A few potential headaches, and ways to avoid them
Searching old mail
My new inbox obviously doesn’t have the history of my old inbox, so I cannot search for old conversations within it. This hasn’t been nearly as painful as one might think; I keep an instance of the old inbox open in a separate browser and use it for searching email history [3]. Whereas searching Gmail was previously synchronous and blocking, it’s now asynchronous, so I can search while still performing other email tasks in my primary window.
Filters and labels
Gmail allows you to export and then import all of your filters in batch. This used to be a Labs feature but seems to now be a Gmail default. I decided that my old account was suffering from label bloat, so I didn’t re-implement all my old labels; I’ve been adding the labels back occasionally as it has become necessary [4].
Contacts
Gmail has a nice feature that automatically creates contacts for autocomplete purposes whenever you email someone. Unless you’ve explicitly turned this off (and why would you do that?) you can export the contacts from your old account and then import them into the new account. The to field in the new account will then autocomplete for everyone you’ve ever emailed.
A future of facades
This isn’t a breaking change; you can always go back. If you’re considering using Gmail as a facade, there’s little downside to giving it a shot. All messages remain in your original account(s), so you can revert to your old, slugglish ways at any point.
Unless Google solves Gmail’s speed problem, some day soon I’ll decide my new account has slowed down. But this time I won’t stress! Instead, I’ll just create a new facade account.
Thanks to Russ D'Souza for being a guinea pig, as well as making several additions to this post.
[1] There are also other, secondary, causes of slowness besides email size. I tried everything I could find online, and while some tips helped incrementally, nothing was close to sufficient.
[2] For me, Boomerang is the killer app for the gmail “platform.” Till Boomerang functionality is available on other mail apps, I’ll never be able to use anything else.
[3] Another alternative would be to do a POP download of all my mail history into a desktop app, like Sparrow. I actually tried this, but was only able to get partial downloads of my account, perhaps due to its size.
[4] Another potential drawback is a lack of label continuity. e.g. if I label all travel-related emails with a travel label, then I can no longer see all travel-related emails in a single place, as labeled emails are split between inboxes. in practice, this hasn’t bothered me–in the rare cases when I need to see a full history of messages with a certain label, I just pull up both mailbox instances at the same time.
I am a big fan of Sinatra. I love the framework for its simple elegance, but I particularly love it because it’s Rack-compatible, and thus can be easily deployed to Heroku. Both Sinatra and Heroku are geared towards facilitating utter, brain-dead web development simplicity. Pairing them together is the fastest way I’ve found to get a website online.
The Heroku docs for deploying a Sinatra app are excellent, but perhaps make the process more intimidating than necessary for novices, if only because the page includes supplementary info for “pure” Rack apps and other Ruby DSLs. Last week I was helping a friend stick his toe in the water with web development. I wanted to show him how easy it could be to have his own site running on a real live URL. I showed him the Heroku docs, but his response wasn’t “holy shit, this is mind-boggling easy.” Which is a shame, because Sinatra/Heroku deserve that response.
So I made my Sinku repo public on Github. This is what I use as a baseline for Sinatra apps. It’s little more than a raw Sinatra repo, but it takes the timeframe for deploying Sinatra to Heroku down to under a mintute. To deploy a site on a Mac, open the Terminal and type the following [1]:
You can then of course edit the contents of index.rb and create other files to personalize the app. But that’s all you need to get something online. You can see the site by typing heroku open in the terminal. You could also create this with a more concise, single-line version:
I create Sinatra apps frequently, often for trivial uses. An example from a few weeks ago: I was sending a long Powerpoint to a big group of people. I was afraid that I’d made a mistake or two in the presentation, and that one of the recipients would point this out before everyone in the group got my email. In case this happened, I wanted to be able to host the file on a Cloud App URL and then stick that URL behind a redirect so I could swap in an updated file if necessary. But no URL shorteners that I use (goo.gl, bit.ly, etc) allow for changing a URL once a shortlink has been created. So, instead, I created Sinatra app that would serve as a redirect. Due to the simplicity of Sinatra and Heroku, I was able to do all of this in a minute or two.
I gave this example to my aforementioned friend. It got him much more engaged in learning to code than the 500+ page intro to Rails book he had. He cloned the Sinku repo and immediately began building a less trivial application in Sinatra. The simplicity of Sinatra and Heroku is great for teaching web development. It’s also quite good at empowering those who are more experienced.
[1] You will obviously want to customize the directory name, “project” in this example. There are a few dependencies necessary to make this work on a fresh OS X installation, including git, bundler, and heroku.
My co-founder and I have run our startup with religious frugality. When first looking for an office, we found a shared workspace that allowed us pay by the area, and we squeezed in folks for $160/mo per person. When traveling for business, I take the search-Hipmunk-and-choose-the-cheapest approach to finding a hotel. When hiring, we have a visceral aversion to using recruiters; engaging a recruiter seems like the ultimate expression of laziness. This sort of diehard cheapness is not original; there are plenty of startups that are even better at it than us. But recently I’ve been rethinking our approach…
Every person at every company has an implicit hourly rate of value they create for the business. Perhaps Bob, our traveling salesman, provides $150 of value for every hour that he’s working [1]. If Bob catches the flu and is forced to spend a day hunched over a toilet rather on the road selling, then the DCF of future SeatGeek earnings decreases by $1,500 [2].
Once he recovers, suppose Bob has to travel across Manhattan for a meeting. He can get there by taking the subway for a modest $2 or by taking a cab for $27; the latter would save him thirty minutes of time. The frugal bootstrapper in me wants Bob to take the subway. But if Bob does that, he is effectively stealing $50 from SeatGeek [3]. Bob’s decision causes our enterprise value to drop by that amount. If a shareholder owned 2% of SeatGeek, she would be $1 poorer after Bob’s choice. It’s optimal for shareholders if Bob leaves for the meeting half an hour later and spends that time working [4].
Once you start thinking like this, your day becomes full of these tradeoffs. Today I had to buy computer for a new employee [5]. I went to Amazon, my go-to online store, and immediately found what I was looking for listed at $700. Based on previous experience, I know that Amazon isn’t usually the cheapest option for laptops; I estimated that if I spent another fifteen minutes diligently searching the web, the expected value of the best price I’d find would be $660. At that moment I was estimating my rate of value creation at over $160/hr, so I bought the Amazon computer and moved on to the next item on my to-do list.
Ideally, if you stop anyone at a company and ask them “at what rate do you value your time right now?” they should respond with a number. Determining that number is really hard; I am still quite poor at estimating my hourly value. But if you don’t have an estimate–no matter how rough–you don’t even have a framework within which to make decisions. You’re living your life by your gut rather than thinking analytically about how you spend your time. People with a number are Billy Beane; those without are Jim Hendry.
The rate at which you value your time value your time is not static; it’s constantly changing. If I’m stuck on a plane with no internet, the rate at which I’m creating value for SeatGeek is low. On the other hand, suppose it’s 3am in the morning and I’m feverishly working on a presentation for a massive client. The presentation will take place in five hours. Here, the rate at which I’m creating value is quite high. If two hours magically disappeared from the clock, it could destroy a meaningful amount of SeatGeek’s enterprise value. So I feel justified in, say, asking my girlfriend to get me a Diet Coke so that I don’t have to break my concentration (thankfully she’s an economics student, so she understands).
The rate at which someone creates value for a company (and thus should value their time, from the perspective of the company) isn’t the same as their wage. In theory, calculating the value of someone’s time is simple: if Bob went into a trance and didn’t work for an hour, how would the company’s DCF of earnings change [6]? The drivers for wage are more complex, but are nicely captured by VORP. In baseball, VORP is a statistic that identifies the incremental value Player A creates vis-à-vis the player that would replace him in the lineup if Player A got injured. If a Player A has low VORP then his team is close to indifferent about keeping him around; he will be paid a relatively low wage.
There are people who create tremendous value but have low VORP. Consider an EMT. The hourly value created by an EMT is enormous; if an EMT went into a trance on the job, she could end a human life. But the market for EMTs is liquid and the difference between the worst EMT that gets hired and the best that can’t find a job is small, so they are not particularly well-compensated. It is natural for people to associate the value of their time with their wage, but that urge is best resisted.
Last week, lots of people in the ticket industry headed to the Bellagio in Las Vegas for Ticket Summit, the largest annual ticketing conference. I went for the third year in a row. The past two years I stayed at the Imperial Palace, which seems to consistently be the cheapest place to stay in NV, despite its location in the middle of the Las Vegas Strip. The frugal-no-matter-what part of my brain drove me there. This year, I changed Palaces; I stayed at Cesar’s. My rationale: the hotel is closer to the conference than the Imperial Palace. I will spend an extra $70/night, but that cost will be more than recouped by the time I save walking back and forth. If I were being completely rational I would have just stayed at the Bellagio itself, but the $250/night price tag was more sticker shock than I could bear. I’m getting better at being coldly analytical about how I spend my time, but now and then my inner cheapskate still shines through.
[1] Bob is fictional. SeatGeek has no traveling salesmen.
[2] I’m making several assumptions here. First, I’m assuming that Bob works ten hour days (excluding lunch breaks, etc). More importantly, I’m talking in terms of expected value. In other words, on a given day Bob might create -$5,000 of enterprise value or $10,000, but I’m assuming that he creates $1,500 on average. I will use expected values throughout this post, but will not disclaim them each time.
[3] I’m making the simplifying assumption that Bob’s time is worthless while he travels. In reality, that’s unlikely–he’s able to think about his upcoming presentation or how to deal with a situation back at the office. But that doesn’t change this decision framework, it just changes the numbers. The analysis here is very much simplified, but as you add complexities the intuition still holds.
[4] I’m speaking here in terms of what’s value-maximizing for SeatGeek, which is not necessarily utility-maximizing for Bob. Bob may adore subway rides and loathe cabs, such that he prefers to get to his meeting slowly even though it reduces the value of SeatGeek. From the perspective of someone running SeatGeek, this is relevant; a more complex analytical framework would account for employee happiness and its impact on retention, productivity, etc. But, to the extent I can influence Bob’s decision when he is close to indifferent, I should incent him to take a cab. In cases when you’re choosing how to spend your time as a founder, short-term personal utility matters even less. If Bob owned 40% of SeatGeek, then he would have to find the subway much more pleasurable (“$20 worth”) in order to justify the slow trip. This is part of the driver for granting employee options.
[5] To the person who says “If you’re so concerned about the value of time, does it make sense for you to be in charge of computer procurement?”: Our office manager was on vacation, and the guy needed a computer to work.
[6] This is the case in static equilibrium, i.e. it assumes that Bob’s trance doesn’t mean that he or his co-workers will stay late to make up for Bob’s mental absence. This can also be analyzed in a more dynamic equilibrium, but as such is harder to lay out simply in a blog post.
We recently hired a new office manager at SeatGeek. It’s possible to find good office manager candidates by posting on sites like Craigslist and Monster, but there’s a big signal-to-noise problem–a single Craigslist post can yield hundreds of resumes, many from unqualified applicants. The cost of posting on Craigslist isn’t $25; the true cost is your time.
Many applicants didn’t know anything about our company or the particulars of the job. Perhaps they did a search on Craigslist for “office manager” and applied to every job they found in rapid succession, hoping to get a few hits. These folks reduce the amount of time I can spend with folks who actually want to work at SeatGeek.
So during the past hiring process, I tried something a little unusual: I required that all applicants complete a short Excel challenge when applying [1]. Importantly, the job involves almost no work with Excel. I was upfront about this in the job post:
Please note that using Excel is not a major component of this job. So why the Excel challenge? We believe that applicants who do well on the challenge are more likely to be smart, computer literate, and good at following instructions.
I got some interesting results. About 50% of applicants sent emails with no Excel attachment. Among the remaining 50%, about half hard-coded answers to the questions rather than using formulas, which the instructions explicitly warned against. So I was able to eliminate 75% of applicants in under 20 seconds. That meant I had more time to spend with the folks who were most qualified.
Among 25% of “good” applicants, I cared little about their answers. I didn’t expect people to get everything right–the final two questions were quite difficult; only 3 out of 500+ got all six questions correct. As long as the person applying had answers that weren’t completely wacky, I considered them to have passed. If they were in the 25% group it meant they were better than most other applicants at following basic instructions.
I’ve been doing something similar when posting freelancing jobs on sites like oDesk. After
you post a job on oDesk, freelancers respond with a bid and a few paragraphs about why they should be selected. So, at the end of my posts, I say something like “This job must be completed by July 20. In your response, please explicitly state the date by which you think you can finish.” If a bidder doesn’t include a date, I assume she didn’t bother to read all the way through.
The person we ended up hiring as our office manager got 4 of 6 Excel questions right. But the email she sent us included a “Notes on the Excel Test” section that described some of the issues she had dealt with. She didn’t need to include that to get an interview, but as soon as I saw it I was completely sold. More than a test of Excel skills, this was a test of how much someone wanted to work at SeatGeek.
[1] One downside of this is that it takes applicants longer to apply, thus potentially scaring off qualified folks. I tried to mitigate this by telling people not to bother writing a cover letter.
For the first eight months after we raised our initial seed round at SeatGeek, I handled all HR myself. This included a bunch of less-than-thrilling activities:
Getting quotes from lots of health insurance providers and signing us up for the best plan. Repeating that process for vision/dental.
Handing all onboarding for new employees, which meant spending a morning wading through a mountain of forms for each new hire.
Paying all sorts of random taxes to New York State [1].
Handing all compliance and government reporting. In retrospect, this is a terrifying thought–I no doubt unintentionally committed a least one act of gross negligence somewhere along they way.
Eight months in, one of our investors convinced me to sign up for a PEO. We chose Administaff, which has since changed their name to Insperity (a portmanteau of “inspiration” and “prosperity”…say it aloud and let a wave of zen wash over you) but I don’t think the particular company matters much–there are other good options. What was important was that I wasn’t doing it myself. Rather than spending 5-10 hrs/week on administrative HR–something I’m mediocre at–I spent that extra time actually building our website [2].
We initially kept HR in-house as a way to save money, but it turns out that using a PEO adds almost no incremental cost. PEOs like Insperity charge about $150/mo per employee, but that amount happens to be almost exactly what we save per month on healthcare due to the fact that our plan is part of a much larger group. We also got a bunch of nice fringe benefits that we could have never have offered previously–things like 401(k) administration, life insurance, and commuter benefits–all of which come as part of the standard PEO package.
[1] It’s bewildering how many small, trivial taxes they collect. I think it’s like a cop’s speed trap–largely just a way to force mistakes and levy fines.
[2] It’s worth emphasizing that I’m only talking about the *administrative* part of HR here. Some people consider other higher-level functions, such as recruiting and maintaining morale, to also fall under the HR umbrella. Those should obviously not be outsourced.
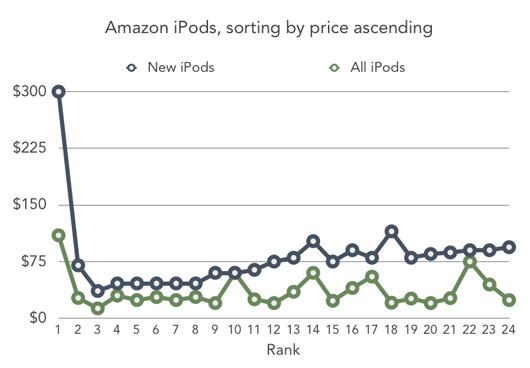
Pretend you’re in the market for a new iPod. You go to Amazon and type in a search. Then, you sort the results by price, low-to-high. For infrequent Amazon users, the results may be surprising [1].
The results are far from monotonic. This is true regardless of whether Amazon’s sort considers only new items or if it also evaluates the price of used items from the “Amazon Marketplace”. The consensus among Amazon pros is that the site uses the latter approach. If that’s the case, only 11 of the 24 iPods on the first page are more expensive than the iPod that immediately precedes it in this rank of “increasing” price.
Why would Amazon fail badly at something that seems so simple? The immediate cause is probably caching. Amazon likely has a task that periodically caches the low price for each item. The inventory of used items in the Amazon Marketplace changes constantly and the cache does not refresh every time an item is sold, so the data quickly becomes stale. Tellingly, if you search for items without many Marketplace listings, the price sort is much more reliable.
Smart folks at Amazon have no doubt tried to solve this [2]. Perhaps they can stop trying; why not just exclude Marketplace items from the price sort calculation altogether? That (probably) solves the monotonicity problem. More importantly, it gives users what they want when they sort by price sort. Doing a price sort is usually a quick way of saying “what is the cheapest type of iPod Apple is currently making?” Including used Marketplace items in the sort algorithm just confuses the answer to that question.
[1] The results in this graph will be stale the moment I hit publish. But I don’t think the overall lack of monotonicity will change much.
[2] …within the confines of running the biggest e-commerce site on Earth. A huge constraint.
Hiring web developers is like simultaneously enduring a flood and a drought. You are overwhelmed with resumes yet struggle mightily to find folks worthy of your team. We seriously consider hiring about 10% of the folks I interview at SeatGeek. Those 10% come back for additional rounds, do longer coding tests, etc. Succeeding in the first stage of the hiring process means efficiently separating the wheat from the chaff. As the initial screen for all applicants, I consider it my job to isolate the 10% as quickly as possible.
I’m starting to realize I rely heavily on a set of heuristics to determine if someone is likely to be in the 10% group. These don’t involve asking the interviewee about his life goals and then staring deeply into his eyes as he answers. They are simple shortcuts–usually yes/no questions. Hackers who fit my profile of the ideal startup web developer are likely to…
Prefer Git for version control. And have a Github profile.
Use OS X as their operating system of choice. Linux is fine too, although surprisingly few interviewees cite it as their primary OS these days. Windows is a red flag.
Read Hacker News. Preferably they have an active profile, as you can learn a lot by reading someone’s comments. (As an aside, I regularly read the Paul Graham micro-blog that these create. Unfortunately I don’t think he’s on the job market.)
Have a personal webpage. About.me doesn’t count, as it communicates “even though I’m a professional web developer, I couldn’t bother throwing up a single page of static markup about myself.”
Choose Ruby or Python as their go-to web development language. This one is far from universal. There are lots of other answers that would not be cause for alarm. Others, such as ASP.NET, would be cause for much alarm indeed.
Be working on personal projects. Ideally he’ll have projects that are simultaneously finished, half-finished, and barely-started. It’s particularly important to have at least one personal project that’s finished–something that’s fully realized, hosted somewhere, and has no obvious bugs. That shows that a developer is able to sort out all the little things throughout the stack that go into building a web app and deploying it into production. (Credit to @erwaller for adding to this bullet.)
Know what Y Combinator is. Hopefully he will he be familiar with TechStars, DreamIt, and other accelerators as well. Anyone who is unaware of YC at this point doesn’t know much about startups, and I see interest in startups as an important component of cultural fit at SeatGeek (thus this wouldn’t be an appropriate consideration for someone hiring at a larger company).
Be comfortable throughout the entire web stack. If someone is an outstanding dev ops guy, for example, he’s still likely to know basic Javascript.
Viscerally averse to uninteresting frontend work like PSD to HTML/CSS conversion (after all design work is done and before any JS/interaction work is done). It just isn’t challenging.
These heuristics work as a negative filter but are useless as an affirmative screen. Just because someone fits the above profile doesn’t mean we’ll hire him; it’s just a first step. By no means do I think a candidate must fit all the above specs in order to be worth pursuing.
By definition, heuristics are fuzzy. I’m cheating. I miss some great people due to the above shortcuts. But, alack, SeatGeek does not yet have an internal recruiting department. It’s just me. This approach is predicated on the belief that due to resource constraints I’m going to miss a non-trivial number of good candidates, so I might as well be efficient in the way I miss those candidates. Many people who lack the above traits are still outstanding developers but I believe they are, on average (and only on average!) less likely to be kick-ass developers at a small web startup.